Dashboard
The Dashboard shows all available workflows, organised into Data Workflows and AI Workflows. Select a pipeline to start your analysis.
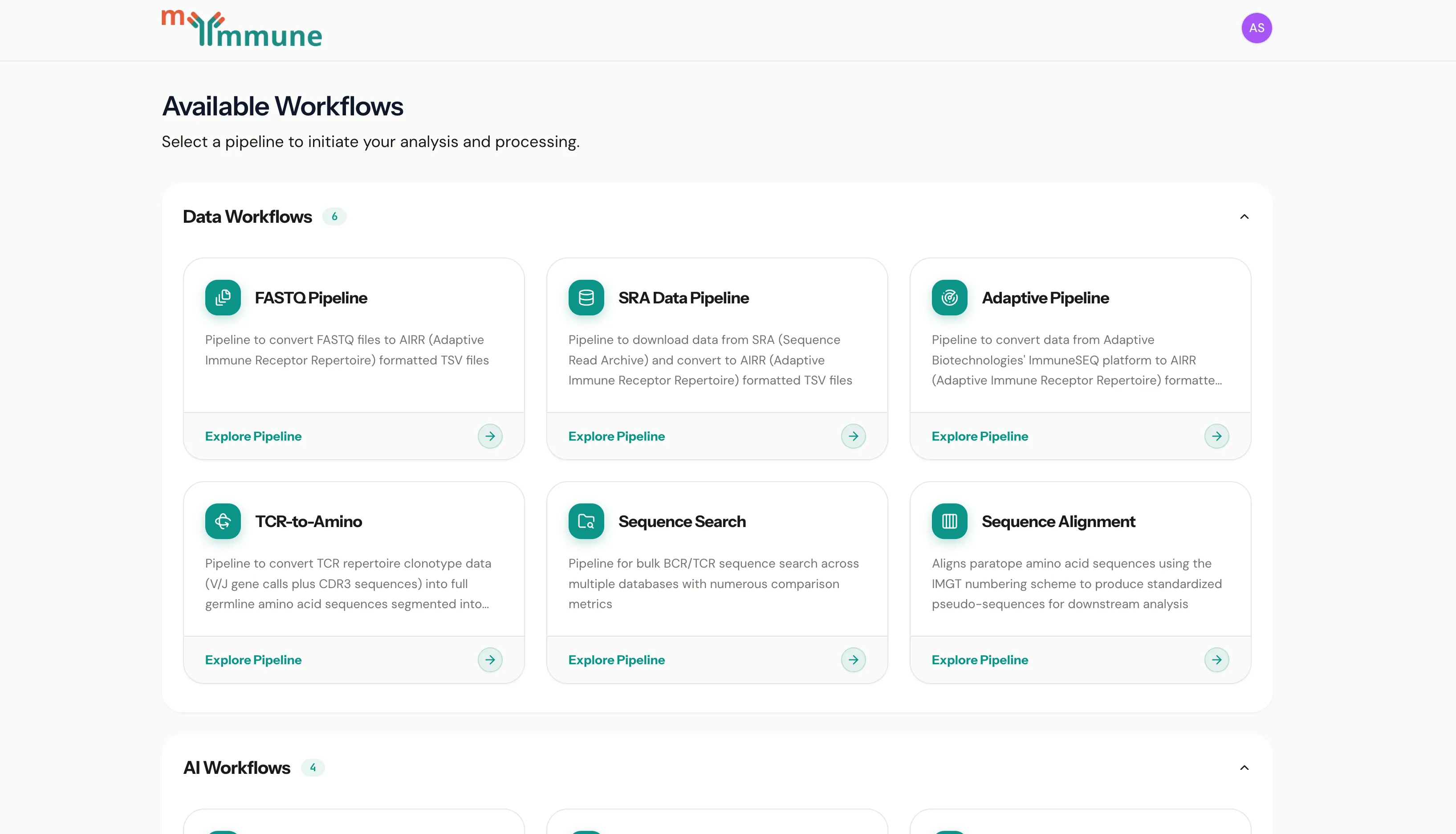
Available Workflows
Section titled “Available Workflows”Data Workflows
Section titled “Data Workflows”| Pipeline | Description |
|---|---|
| FASTQ Pipeline | Convert FASTQ files to AIRR-formatted TSV files with V(D)J gene calls |
| SRA Data Pipeline | Download data from SRA (Sequence Read Archive) and convert to AIRR format |
| Adaptive Pipeline | Convert data from Adaptive Biotechnologies’ immunoSEQ platform to AIRR format |
| TCR-to-Amino | Convert TCR repertoire clonotype data (V/J gene calls plus CDR3 sequences) into germline amino acid sequences |
| Sequence Search | Bulk BCR/TCR sequence search across multiple databases with numerous comparison metrics |
| Sequence Alignment | Align paratope amino acid sequences using the IMGT numbering scheme to produce pseudo-sequences for downstream analysis |
AI Workflows
Section titled “AI Workflows”AI Workflows appear in the lower section of the dashboard. These pipelines build on processed AIRR data to perform clustering, stratification, and prediction tasks.
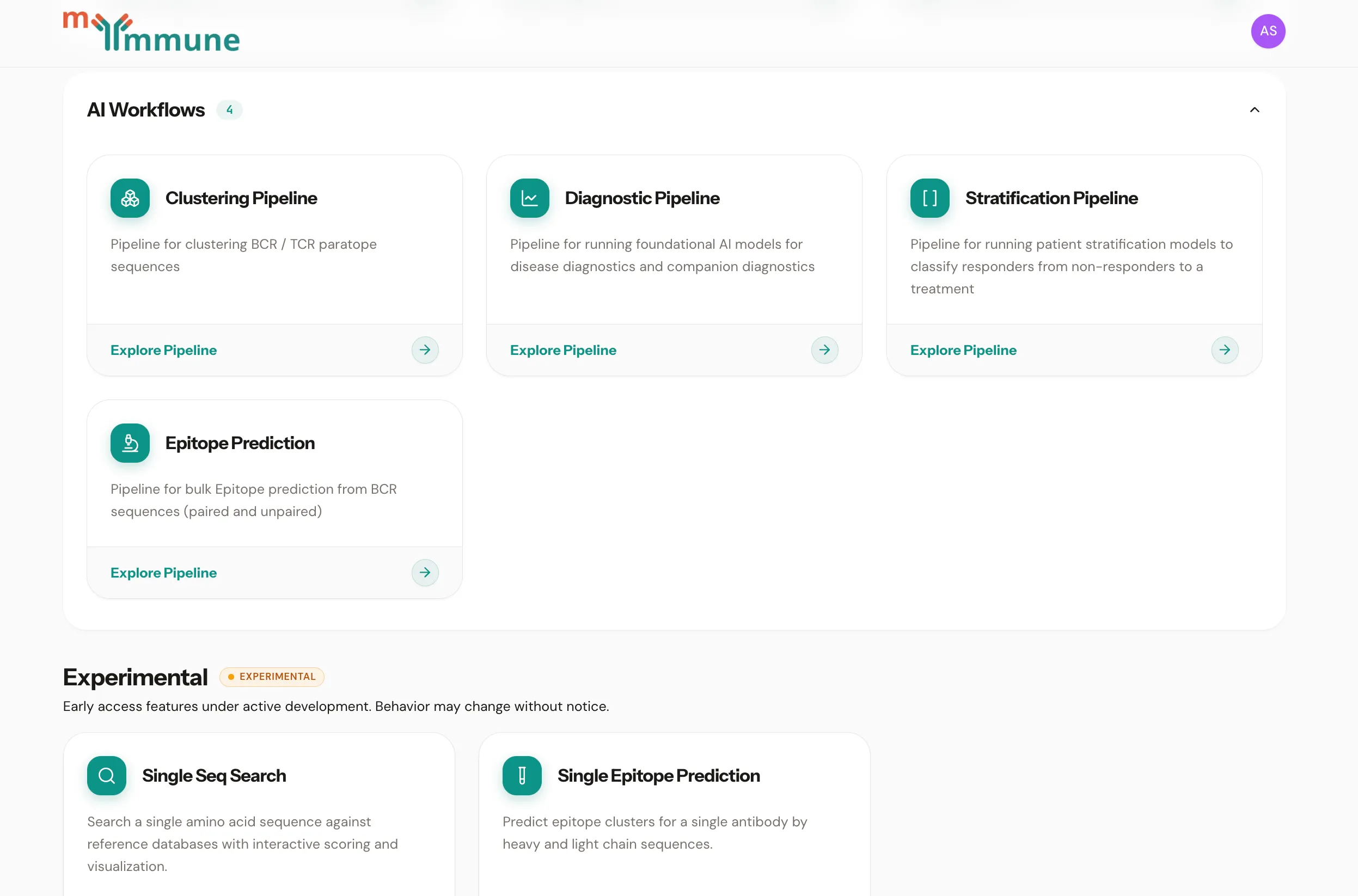
| Pipeline | Description |
|---|---|
| Clustering Pipeline | Cluster BCR / TCR paratope sequences |
| Diagnostic Pipeline | Run foundational AI models for disease diagnostics and companion diagnostics |
| Stratification Pipeline | Run patient stratification models to classify responders from non-responders to a treatment |
| Epitope Prediction | Bulk epitope prediction from BCR sequences (paired and unpaired) |
Experimental
Section titled “Experimental”Experimental pipelines are under active development. Behavior may change without notice.
| Pipeline | Description |
|---|---|
| Single Sequence Search | Search a single amino acid sequence against reference databases with interactive scoring and visualization |
| Single Epitope Prediction | Predict epitope clusters for a single antibody by heavy and light chain sequences |
Navigating to a pipeline
Section titled “Navigating to a pipeline”Click on any card to open that pipeline’s job list. From there you can create a new job, view past runs, and manage presets.
Recent jobs
Section titled “Recent jobs”The job list for each pipeline shows status (queued, running, success, failed) and updates automatically while jobs are running.